작성중 : 2022.09.04

웹 크롤링은 웹 문서(보통 HTML 포맷)를 수집하는 활동, 스크래핑은 수집한 웹 문서에서 필요한 정보를 추출하는 활동이라고 할 수 있습니다.
보통의 웹 사이트는 크롤링 허가 여부에 대한 정보를 사이트 URL + '/robots.txt'로 제공하기도 합니다.
아래 네이버 뉴스 사이트는 user-agent 'Yeti'에 대해서만 일부 페이지에 대한 크롤링을 허락함을 기술하고 있습니다.
https://news.naver.com/robots.txt
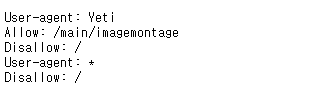
▶ 웹 크롤링 및 스크래핑 관련 파이썬 라이브러리들
- beautifulsoup4
- html5lib
- lxml
- requests
- selenium
- urllib (파이썬 표준 라이브러리)
파이썬 파일에서 beautifulsoup4는 아래의 이름으로 import 합니다.
import bs4▶ requests 라이브러리 사용 웹 페이지 정보 가져오기
아래는 requests 라이브러리를 사용해 임의 웹 페이지 정보를 가져오는 예로 requests의 get() 함수를 사용합니다.
import requests
url = 'https://www.google.com/'
response = requests.get(url)
print(response.url)
print(response.encoding)
print(response.status_code) # 200 = requests.codes.ok
print(response.text)
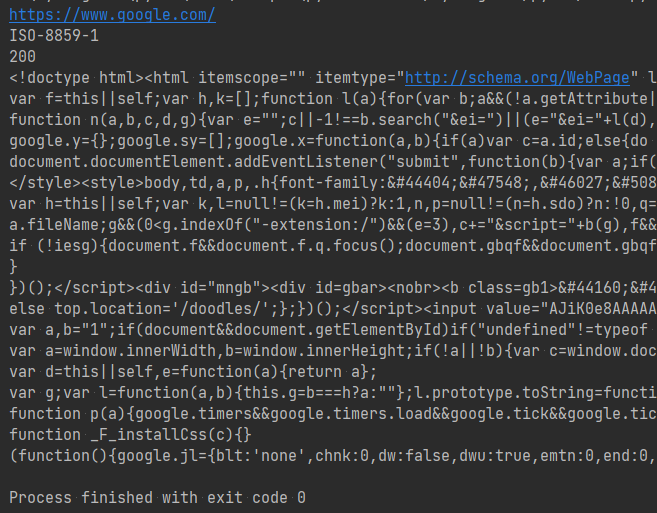
requests의 get() 함수를 호출하면, 내부적으로 requests.request() 함수가 실행되며 'method' 값으로 'get'이 전달됩니다. requests.get() 함수는 HTTP request의 결과로 requests.Response 클래스를 반환합니다.
def get(url, params=None, **kwargs):
r"""Sends a GET request.
"""
def request(method, url, **kwargs):
"""Constructs and sends a :class:`Request <Request>`.
"""
class Response(object):
"""The :class:`Response <Response>` object, which contains a
server's response to an HTTP request.
"""
HTTP(Hyper Text Transfer Protocol)에서 사용하는 메시지는 header(헤더)와 body(바디)로 구성되는데, get() 함수는 웹 페이지 제공 서버에 전달할 내용을 header에 포함시키고 post() 함수는 body에 포함시키는 차이가 있습니다.
response = requests.get(url, headers={'user-agent': 'my-app/0.0.1'})▶ beautifulsoup4 라이브러리 사용 수집한 웹 페이지 정보 분석
아래는 requests를 이용해 수집한 임의 웹 페이지 정보를 beautifulsoup4 라이브러리로 분석하는 예입니다.
- 가져오는 웹 페이지는 네이버 뉴스
import requests
from bs4 import BeautifulSoup
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EB%A1%9C%EB%B4%87'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
print('*' * 80)
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.meta)
print(soup.p['class'])
print(soup.div['id'])
print(soup.a)
위 코드는 BeautifulSoup 클래스를 이용해 BeautifulSoup 객체를 생성한 후 prettify() 함수로 웹 페이지 정보를 들여쓰기 등이 적용된 포맷으로 출력합니다.
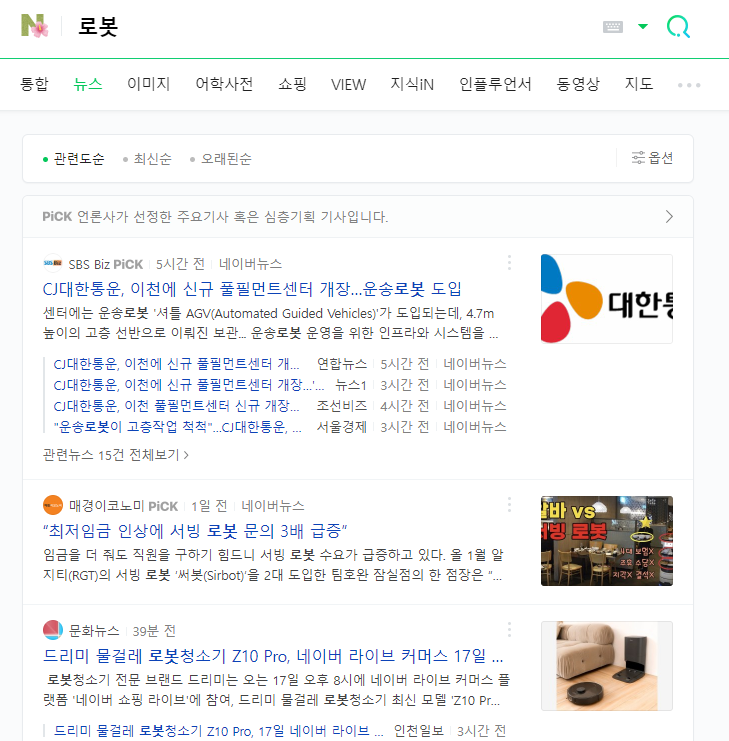
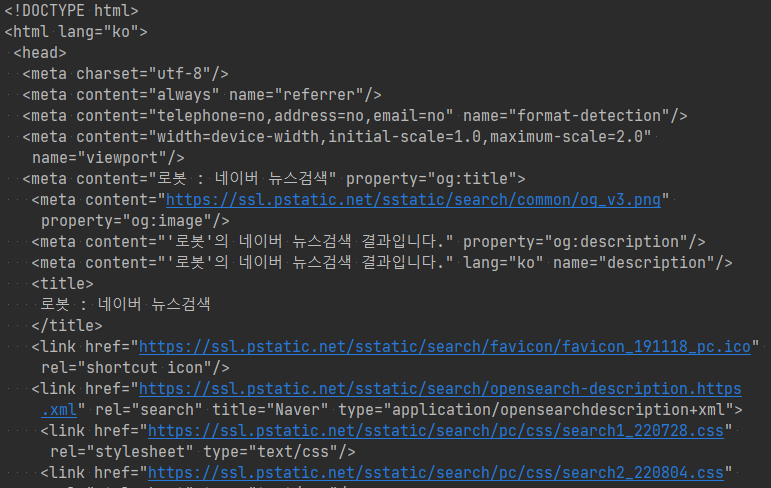
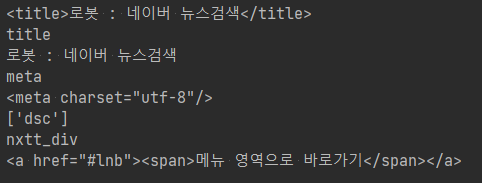
이후의 코드로 웹 페이지의 타이틀 정보나 웹 페이지 내 몇 가지 태그(예. title, meta, p, div, a)의 정보가 출력됩니다.
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.meta)
print(soup.p['class'])
print(soup.div['id'])
print(soup.a)
▶ BeautifulSoup 클래스의 find() 및 find_all() 함수를 이용한 정보 검색
아래의 코드는 BeautifulSoup 클래스의 find() 및 find_all() 함수를 이용해 하이퍼링크를 의미하는 a 태그의 정보를 검색, 그 결과를 출력하는 예입니다.
find_all() 함수는 검색된 정보를 리스트(클래스 ResultSet(list))로 반환합니다.
find() 및 find_all() 함수의 반환값인 Tag 클래스 객체에 대하여 get() 메서드 또는 get_text() 메서드를 사용해 원하는 정보를 추출할 수 있습니다. 예. 속성값 또는 Text값 등등
import requests
from bs4 import BeautifulSoup
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EB%A1%9C%EB%B4%87'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
a = soup.find('a')
print(a)
print(' ', a.get('href')) # = a['href']
print(' ', a.get_text()) # = print(a.text)
for a in soup.find_all('a')[:5]:
print(a)
print(' ', a.get('href')) # = a['href']
print(' ', a.get_text()) # = print(a.text)

find() 또는 find_all() 함수는 html 문서 내 정의되어 있는 순서에 따라 검색된 결과를 반환합니다.
따라서 임의 웹 페이지 내에서 원하는 정보를 추출하기 위해서는 추가의 설정들이 필요합니다.
import requests
from bs4 import BeautifulSoup
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EB%A1%9C%EB%B4%87'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tag = soup.find(name='a')
print(tag.prettify())
print(tag.get_text())
print(tag.contents)
print('\n', '-' * 50, '\n')
tag = soup.find(name='a', attrs={'class': 'news_tit'})
print(tag.prettify())
print(tag.get_text())
print(tag.contents)
tag = soup.find('a', 'news_tit')
print(tag.get_text())
tag = soup.find(name='a', class_='news_tit')
print(tag.get_text())
tag = soup.find(class_='news_tit')
print(tag.get_text())
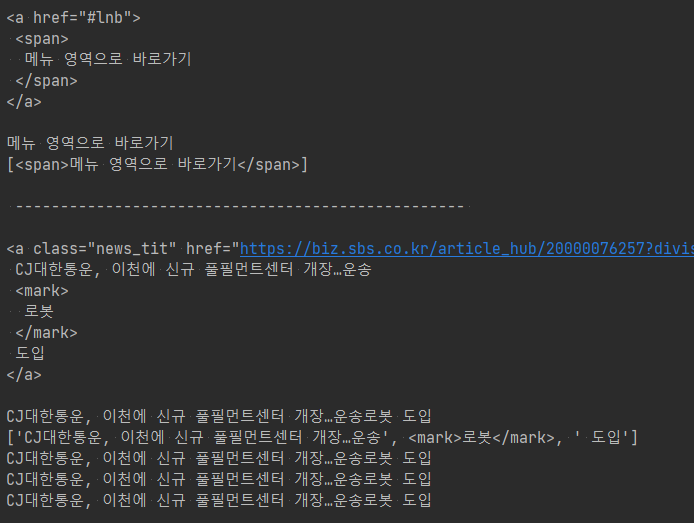
find 메서드 정의는 다음과 같습니다.
def find(self, name=None, attrs={}, recursive=True, text=None, **kwargs):
네이버 뉴스에서 첫번째 뉴스 제목은 "CJ대한통운, ..."입니다.

그리고 이 첫번째 뉴스 제목에 대한 html 코드는 아래와 같습니다. 크롬 브라우저의 경우 F12 키를 눌러 이를 확인할 수 있습니다.

따라서 위에 작성한 다음의 코드들은 a 태그 또는 임의 태그 내 class 속성값이 news_tit인 태그를 검색하는 코드입니다.
tag = soup.find(name='a', attrs={'class': 'news_tit'})
tag = soup.find('a', 'news_tit')
tag = soup.find(name='a', class_='news_tit')
tag = soup.find(class_='news_tit')
Tag 클래스의 attrs 멤버(딕셔너리 타입)를 이용하면 검색된 태그의 속성 정보를 확인할 수 있습니다.
for attr in tag.attrs.items():
print(attr)


네이버 뉴스에서 a 태그 내 title 속성값을 이용해 원하는 뉴스 제목을 추출할 수 있습니다.
import requests
from bs4 import BeautifulSoup
import re
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EB%A1%9C%EB%B4%87'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tag = soup.find('a', {'class': 'news_tit', 'title': '위니아에이드, 자율주행 서비스 로봇 전문업체와 협력'})
print(tag.get_text())
tags = soup.find_all('a', {'class': 'news_tit', 'title': [re.compile('AI'), re.compile('자율주행')]})
for tag in tags:
print(tag.get_text())

▶ BeautifulSoup 클래스의 select_one() 및 select() 함수를 이용한 정보 검색
메서드 select_one() 또는 select()를 사용해 정보의 검색 및 추출이 가능합니다.
아래의 코드는 태그명이 a이고 태그의 class 속성값이 news_tit인 태그의 text 값을 출력하는 코드입니다.
import requests
from bs4 import BeautifulSoup
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EB%A1%9C%EB%B4%87'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# select_one('태그명.class값')
# select_one('.class값')
# select_one('태그명[속성명="속성값"]')
# select_one('[속성명]')
# select_one('태그명 > 태그명 > ...')
# select_one('태그명.class값 > 태그명.class값 > ...')
# ...
print(soup.select_one('a.news_tit').text)
# = print(soup.select_one('a[class="news_tit"]'))

아래의 코드는 태그명 title 또는 p 또는 임의 태그 내 class 속성값이 news_tit인 모든 태그 정보를 출력하는 코드입니다.
import requests
from bs4 import BeautifulSoup
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EB%A1%9C%EB%B4%87'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for tag in soup.select('title, .news_tit, p'): # select('태그명, 태그명, ...')
print(tag)

select_one() 또는 select() 메서드에 대하여 class 속성과 유사하게 id 속성은 '#' 문자를 사용합니다.
아래의 코드는 웹 페이지 문서에서 id 속성값이 nxtt_div인 첫번째 임의 태그 정보를 출력하는 코드입니다.
# select_one('태그명#id값')
# select_one('#id값')
print(soup.select_one('#nxtt_div'))
# = print(soup.select_one('[id="nxtt_div"]'))▶ BeautifulSoup의 HTML 파서
| python html.parser | soup = BeautifulSoup(markup, 'html.parser') | batteries included, not as fast as lxml, less lenient than html5lib |
| lxml html parser | soup = BeautifulSoup(markup, 'lxml') | very fast, external C dependency |
| lxml xml parser | soup = BeautifulSoup(markup, 'xml') | very fast, external C dependency |
| html5lib parser | soup = BeautifulSoup(markup, 'html5lib') | extremely lenient, very slow |
현재 BeautifulSoup 다큐먼트 웹 페이지는 빠른 속도를 이유로 lxml 파서 사용을 권장하고 있습니다.
아래 표를 통해 각 파서의 차이를 간략히 확인할 수 있습니다.
| print(BeautifulSoup('<a><b/></a>', 'html.parser')) | <a><b></b></a> |
| print(BeautifulSoup('<a><b/></a>', 'lxml')) | <html><body><a><b></b></a></body></html> |
| print(BeautifulSoup('<a><b/></a>', 'html5lib')) | <html><head></head><body><a><b></b></a></body></html> |
▶ selenium 라이브러리
selenium은 웹 브라우저 제어를 위한 다양한 기능을 제공하는 파이썬 라이브러리입니다.
selenium 사용 시 실제 웹 브라우저를 제어할 드라이버 실행 파일이 필요하며, 크롬 브라우저의 경우 크롬 드라이버(chromedriver.exe)가 필요합니다.
크롬 드라이버는 아래 경로에서 사용 PC에 맞는 버전을 다운로드하면 됩니다.
https://chromedriver.chromium.org/downloads
| Keys.ENTER Keys.RETURN |
엔터 |
| Keys.SPACE | 스페이스 |
| Keys.ARROW_UP Keys.ARROW_DOWN Keys.ARROW_LEFT Keys.ARROW_RIGHT Keys.PAGE_UP Keys.PAGE_DOWN |
방향 |
| Keys.BACK_SPACE | 백스페이스 |
| Keys.DELETE | 딜리트 |
| Keys.CONTROL Keys.ALT Keys.SHIFT Keys.TAB |
|
| Keys.F1~F9 | |
| Keys.EQUALS Keys.ESCAPE |
'코딩 > 파이썬과 웹크롤링' 카테고리의 다른 글
| 파이썬 웹 크롤링 : HTML 태그 (_작성중_) (0) | 2022.08.14 |
|---|